
Sequences
Designed and developed while at Chatterbug
The Problem
At Chatterbug, we helped people learn new languages (50-sec video of me trying to explain what we do in German below).
Our platform worked well for single words, but we wanted to teach phrases/groups of words that flow together naturally.
Simply adding full sentences to our existing curriculum revealed two painful problems:
- Students struggled. Typing out complete phrases repeatedly felt tedious and discouraging.
- We couldn't predict all the right answers. A German phrase might have dozens of valid English translations, making it impossible to anticipate every correct response.
These weren't just technical problems, they actively interrupted the learning experience.
Translation Prediction Problem
When you're asked to translate a German phrase into English such as:
🇩🇪 Wo ist hier die nächste U-Bahn Station?
How many different English translations could someone provide? There are probably around 30 permutations:
- Where is the nearest subway station?
- Where is the nearest subway stop?
- Where is the closest subway station?
- Where is the closest subway stop?
- Where is the next subway station?
- Where is the next subway stop?
- Where is the nearest train station?
- Where is the nearest train stop?
- Where is the closest train station?
- Where is the closest train stop?
- Where is the next train station?
- Where is the next train stop?
- Where is the nearest Tube station?
- Where is the nearest Tube stop?
- Where is the closest Tube station?
- Where is the closest Tube stop?
- Where is the next Tube station?
- Where is the next Tube stop?
- Where is the nearest Underground station?
- Where is the nearest Underground stop?
- Where is the closest Underground station?
- Where is the closest Underground stop?
- Where is the next Underground station?
- Where is the next Underground stop?
- Where is the nearest metro station?
- Where is the nearest metro stop?
- Where is the closest metro station?
- Where is the closest metro stop?
- Where is the next metro station?
- Where is the next metro stop?
We were seeing hundreds of support tickets where students provided translations we hadn't anticipated. Students felt penalized for responses that were perfectly correct, leading many to abandon their study sessions.
Solution: Constraints That Create Better Experiences
Instead of trying to solve the impossible problem of predicting every translation, I focused on constraints that would improve the student experience:
- Break phrases into learnable chunks that could be tested individually but always in context
- Only test target language input (which has more pedagogical value than native language translation)
- Design the system to feel natural and progressive rather than mechanical
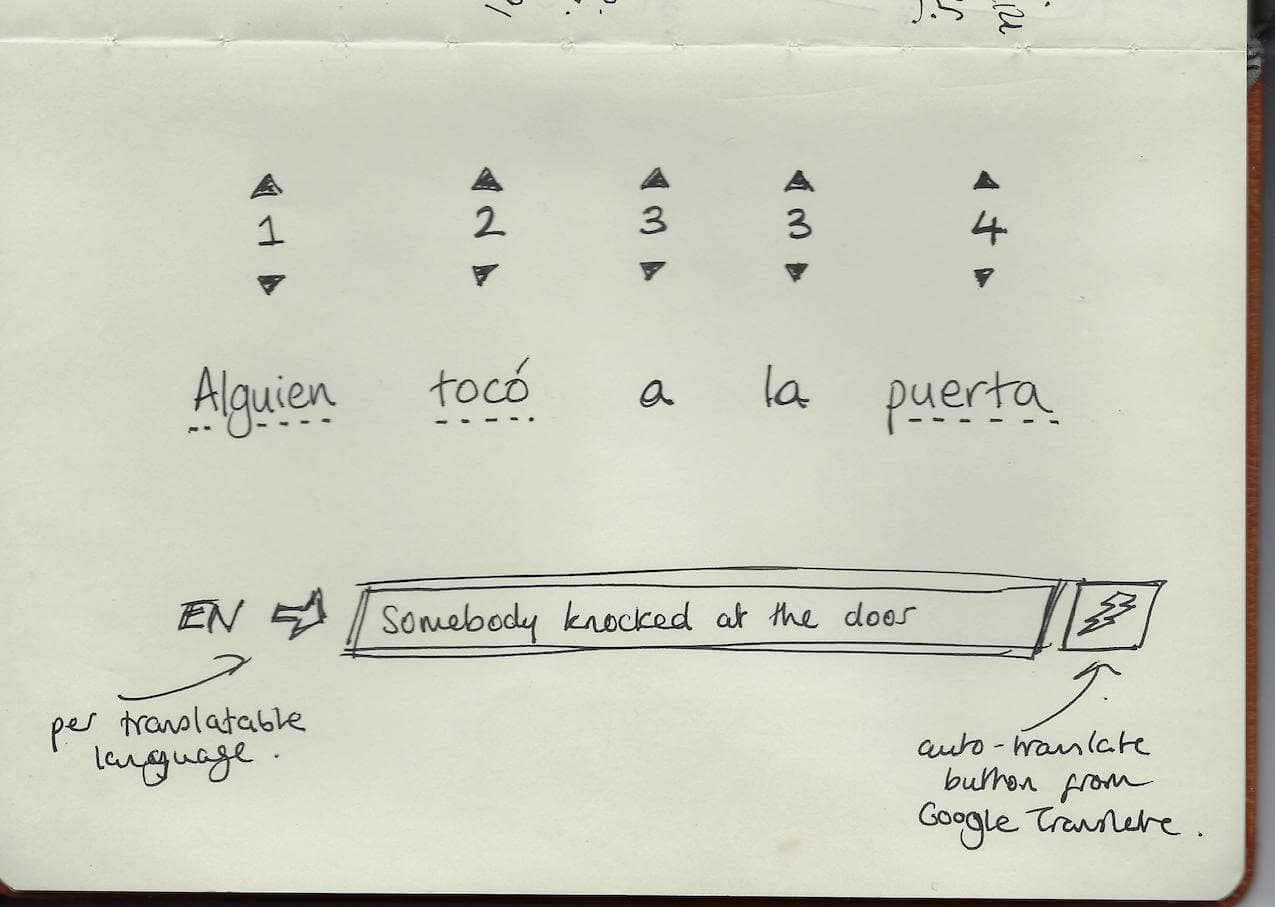
The core idea was simple: instead of overwhelming students with full phrases, let them build confidence by mastering one piece at a time while seeing how it fits into the whole.
Building for the People Who Create
While solving the student problem was essential, I also had to consider our linguistics team, the people who would use this tool daily to create content. Their experience mattered just as much.
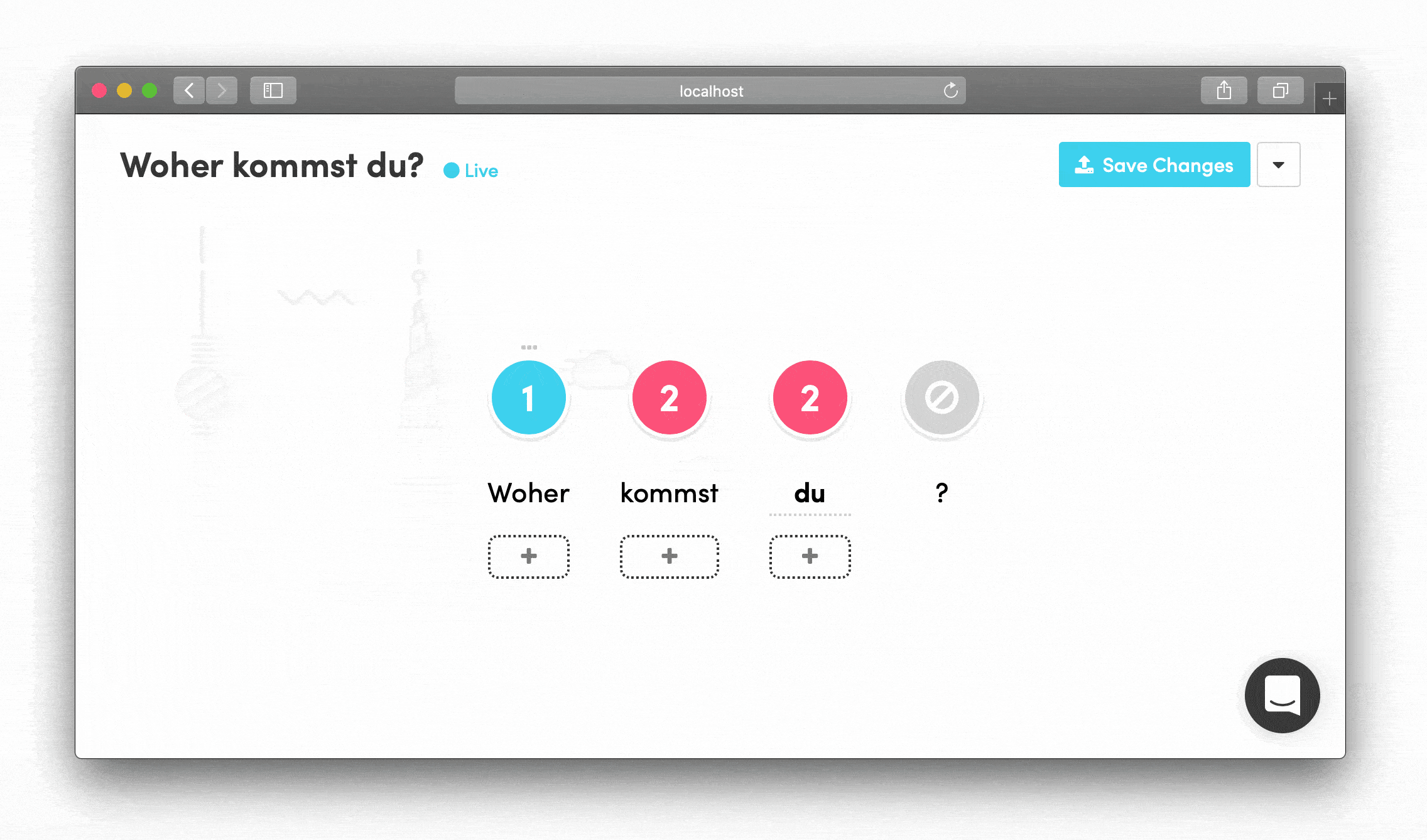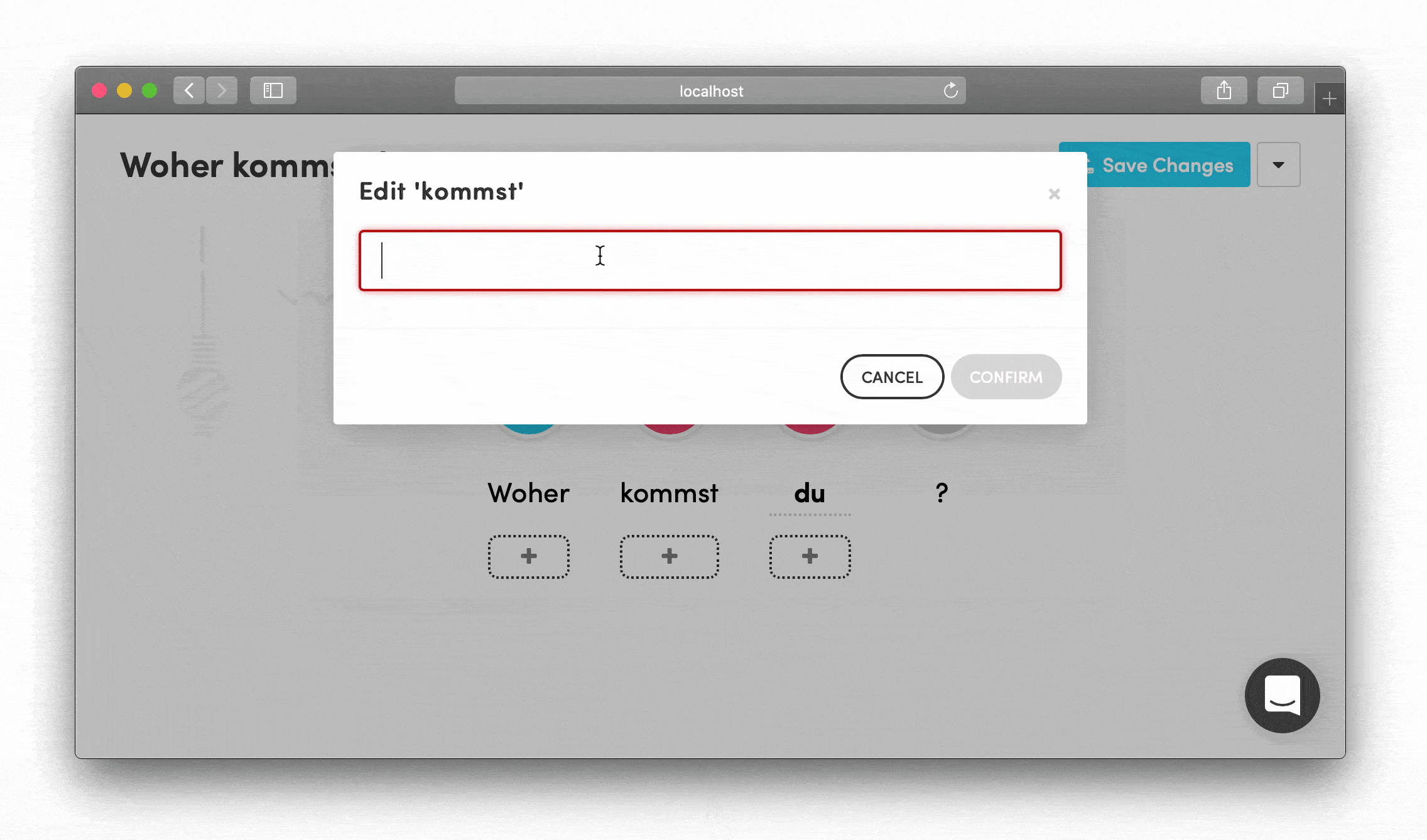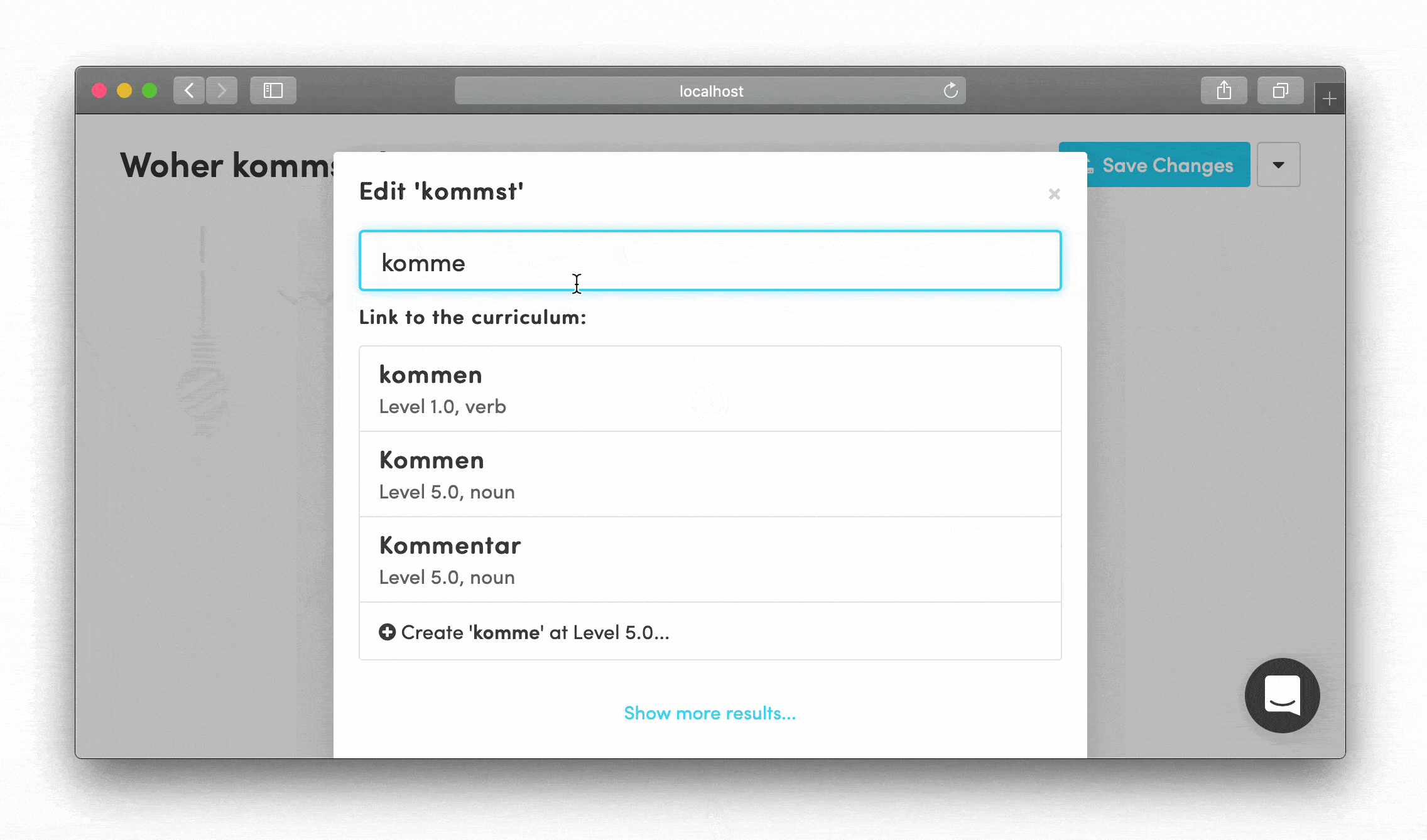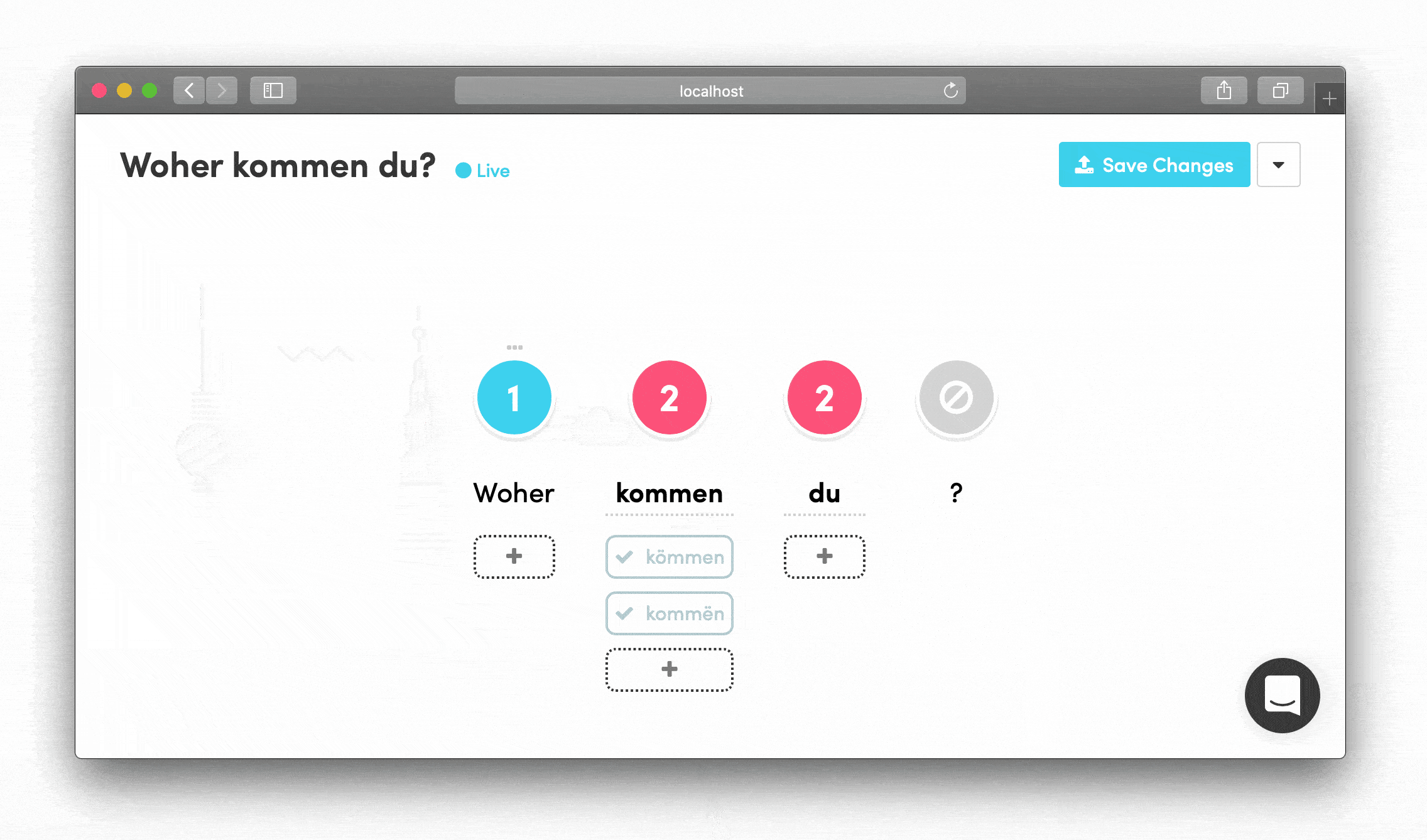
I learned that our linguistics team preferred visual, drag-and-drop interfaces where they could see the entire situation in a single glance. That's how they shared ideas with each other in Slack. This insight shaped every interaction design decision.
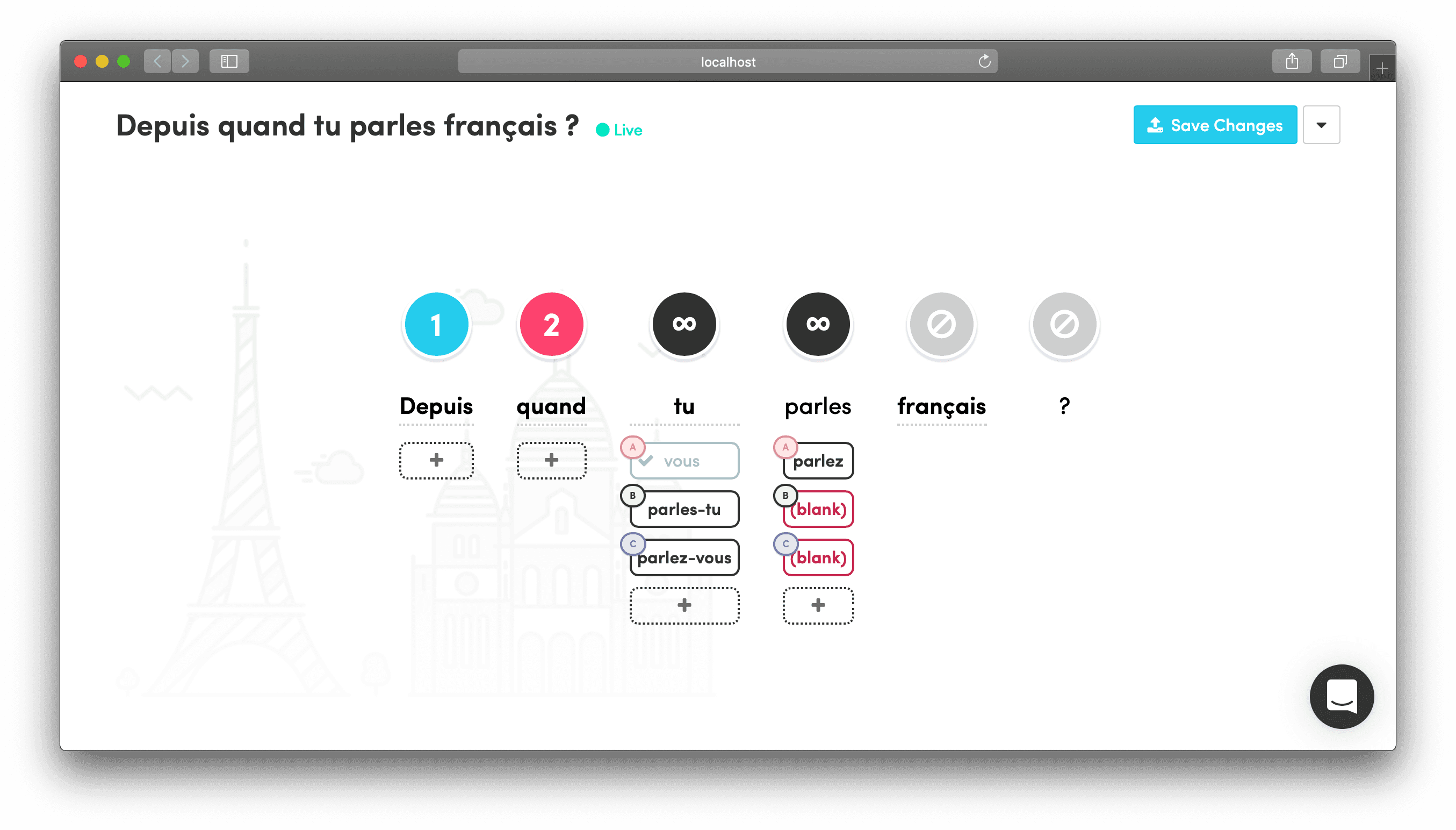
The system I built let them:
- Add alternative translations visually for each word chunk
- See the entire phrase structure at once
- Test their content immediately without technical barriers
Polishing the Invisible Details
Quality shows up in details that users might never consciously notice but definitely feel. For the student experience, I focused on making wrong answers feel encouraging rather than punishing.
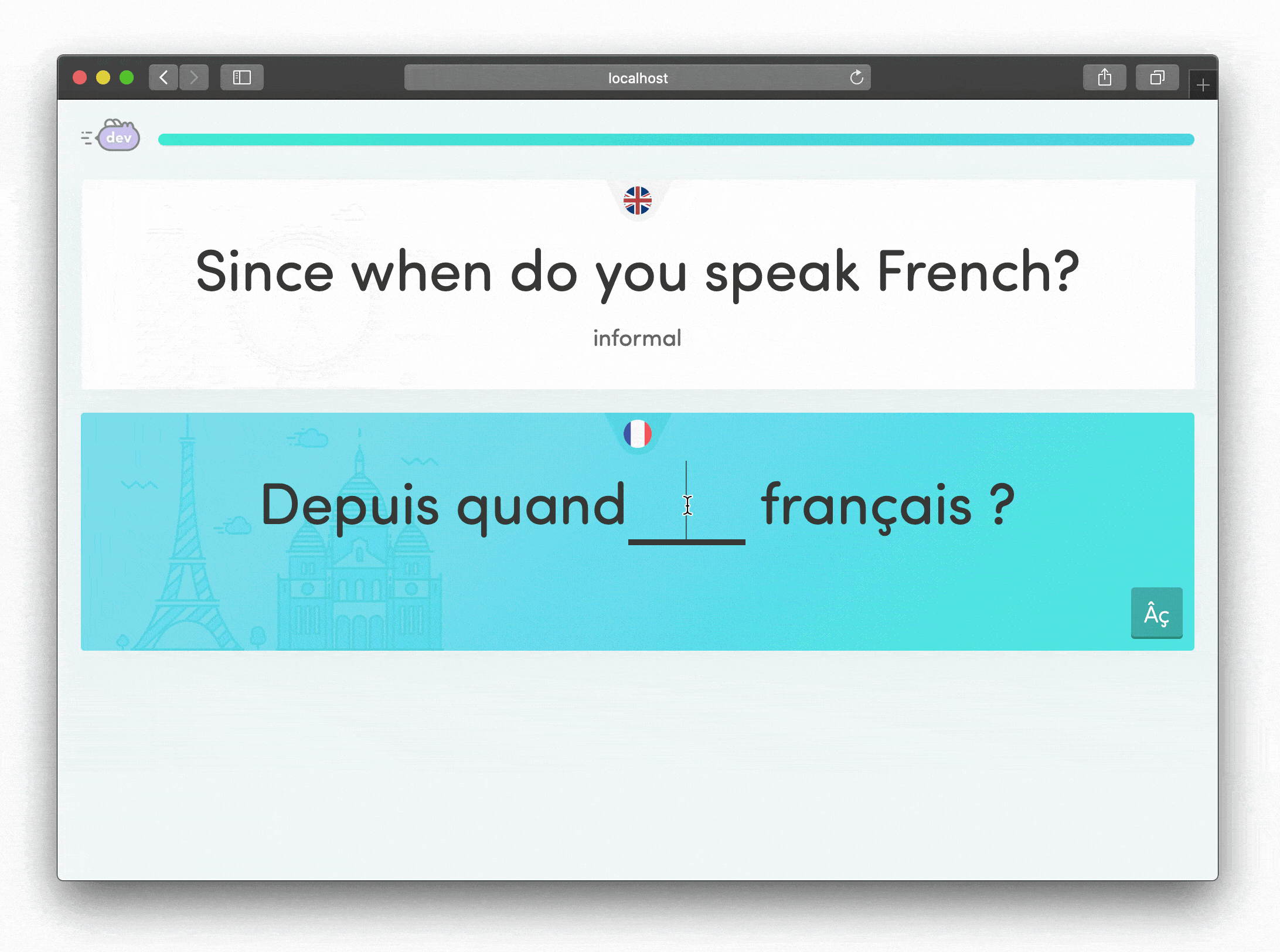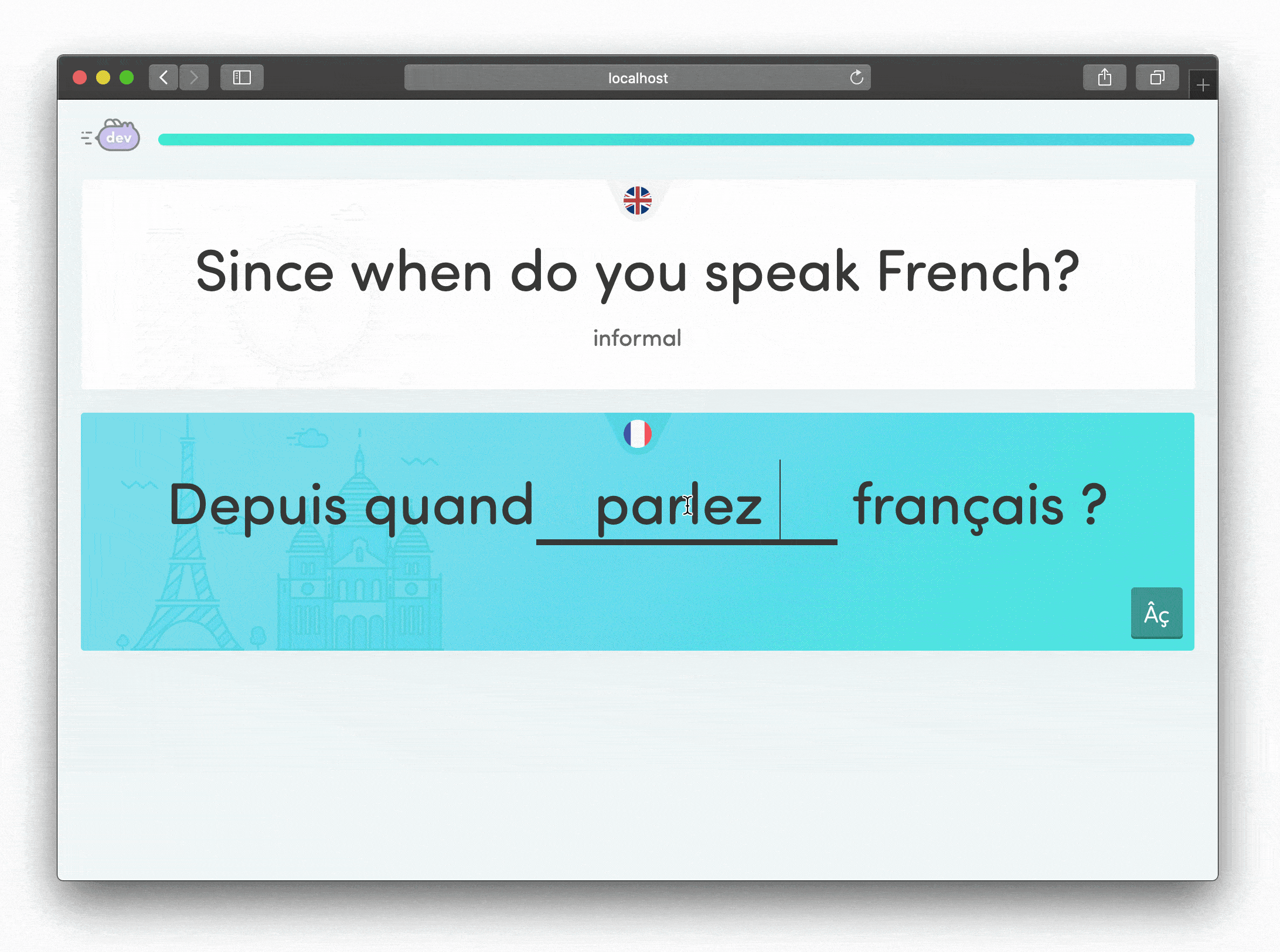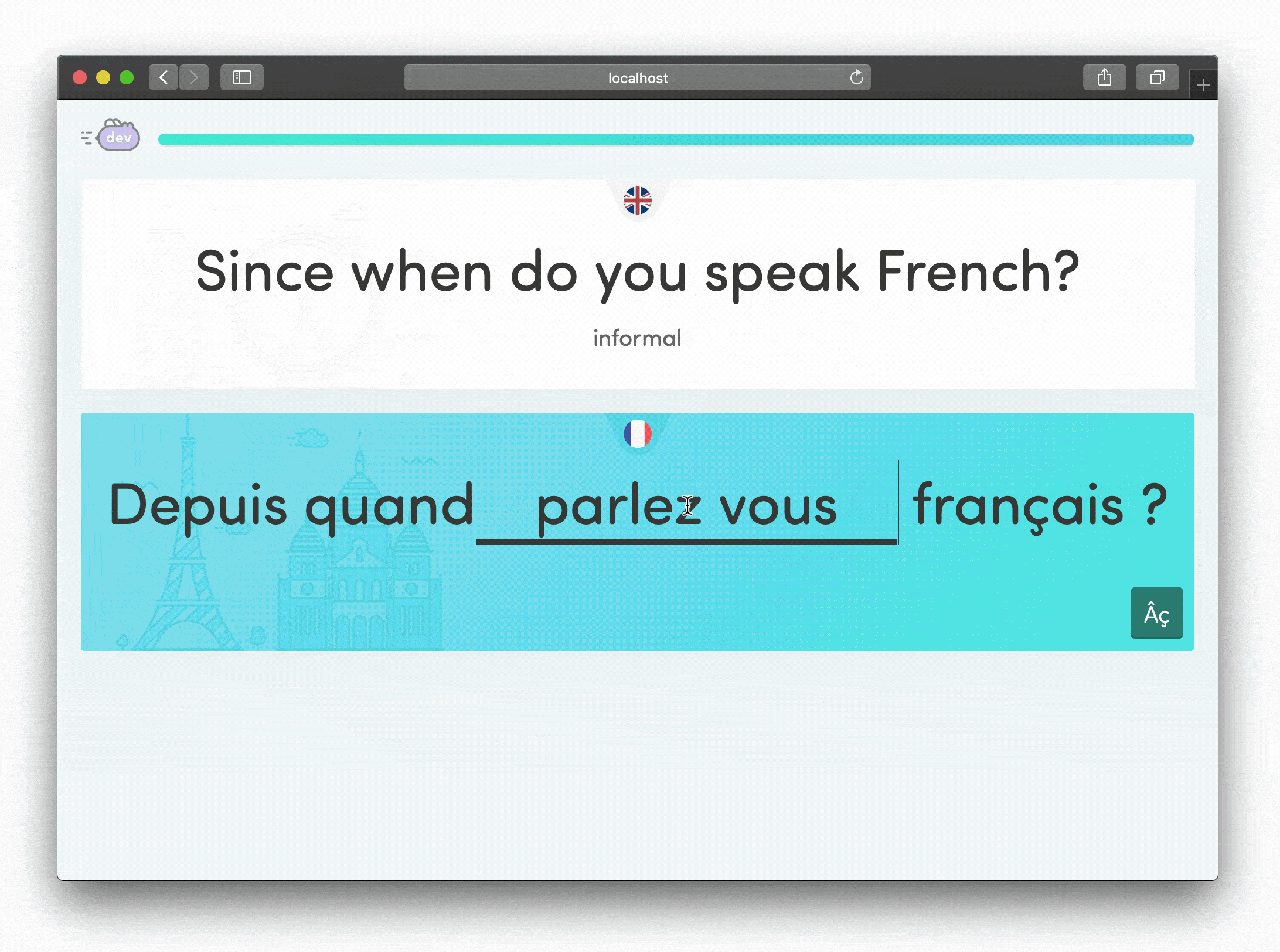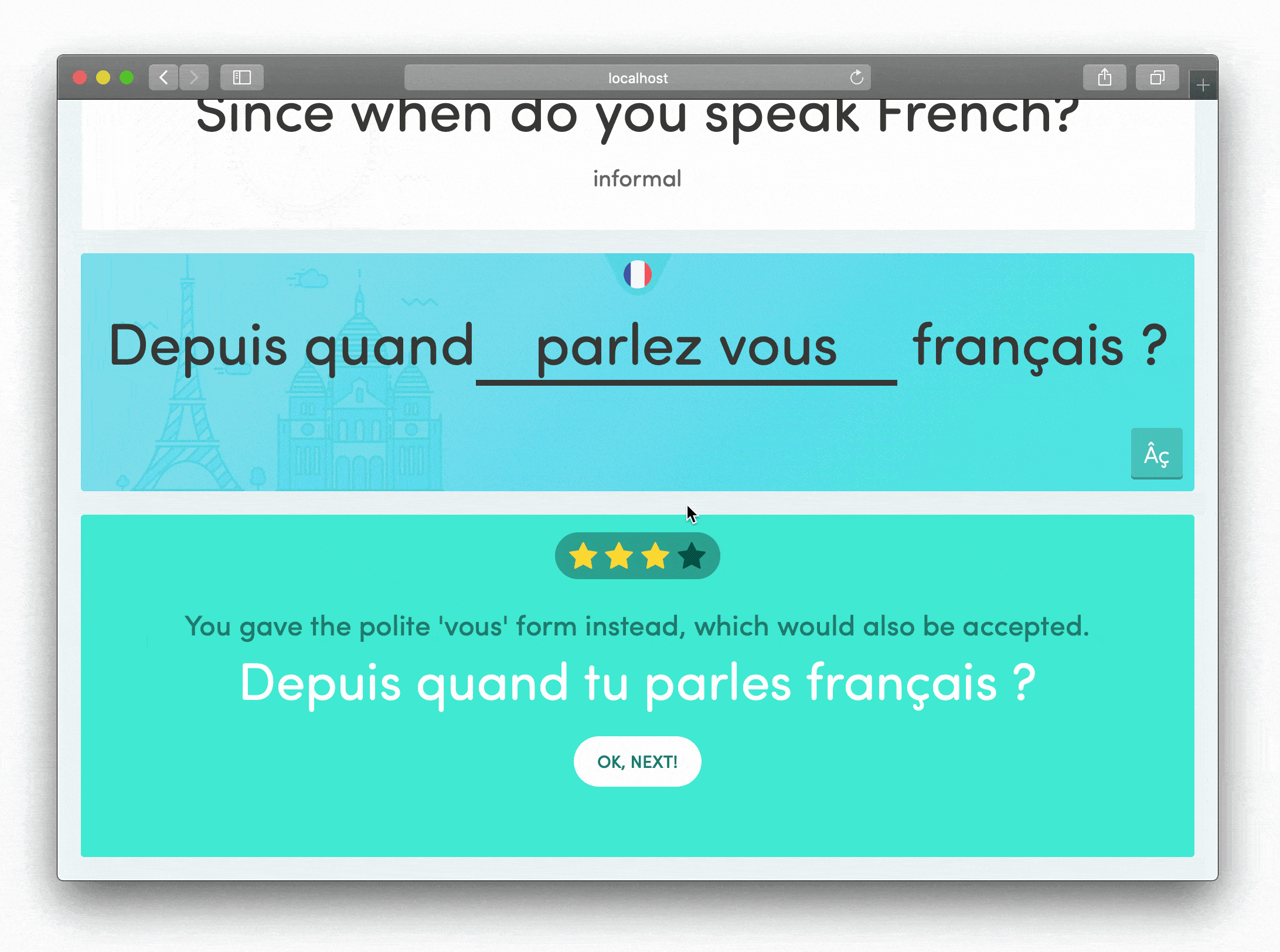
When students provided alternative translations we'd anticipated, they could still progress but received gentle guidance that their answer was non-standard. This felt supportive rather than discouraging, a small detail that made a big difference in how students experienced the learning process.
Results
The focus on both student and creator experience paid off:
- 54% reduction in missing answers compared to our previous phrase approach
- Dramatically fewer customer support requests about phrases
- A tool the linguistics team genuinely enjoyed using and wanted to build upon
More importantly, students could learn phrases naturally without the frustration that had been blocking their progress.
Design Engineering in Practice
This project captures what I think design engineering is about: deeply understanding user problems, moving fluidly between design and implementation, and focus on quality even when it doesn't show up in metrics, because it shows up in the experience.
Some technical decisions that improved the human experience:
Visual Feedback Systems Numeric steppers were color-coded and responded to both left-click (increase) and right-click (decrease)—small touches that made the interface feel intuitive for content creators.
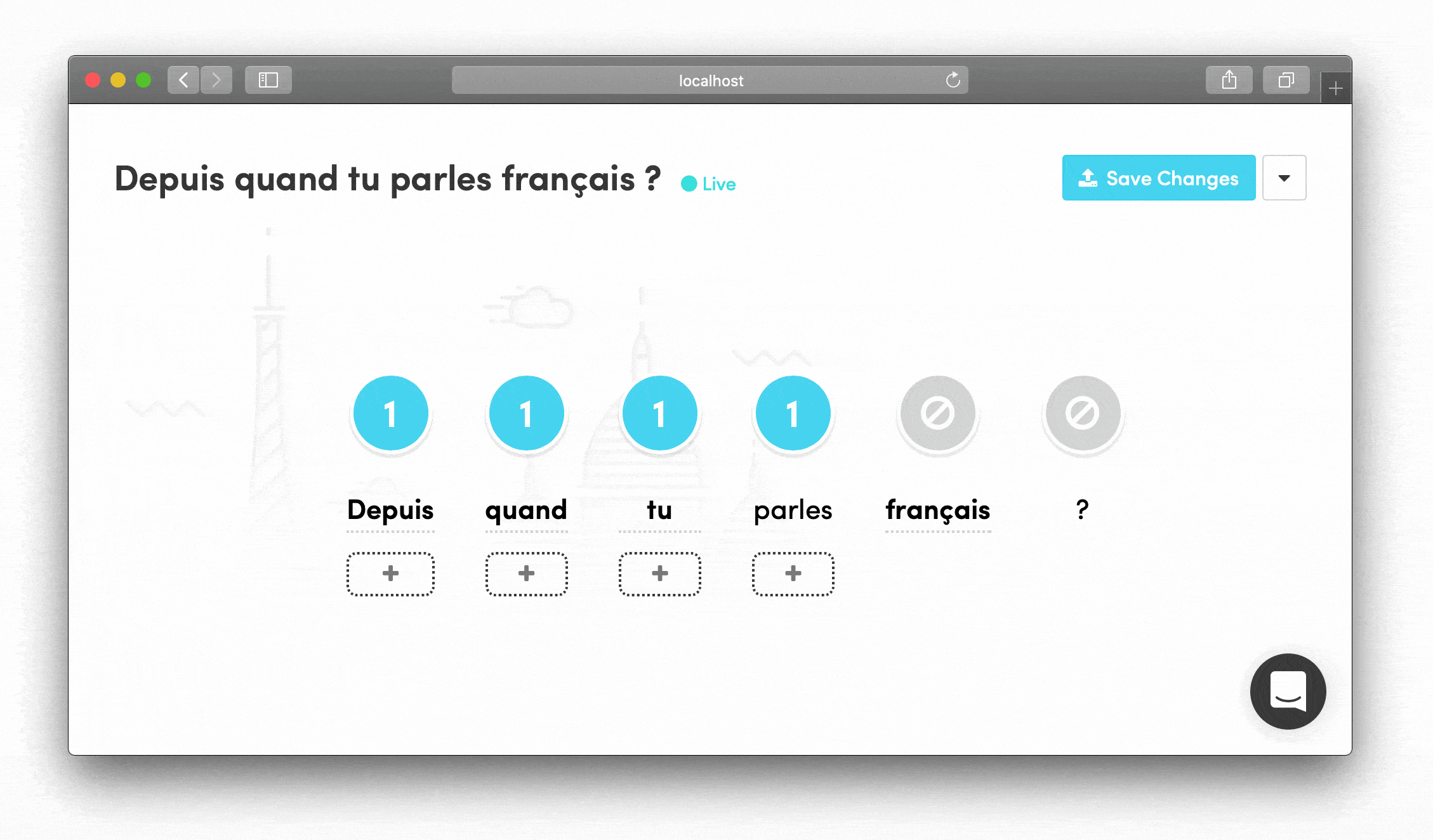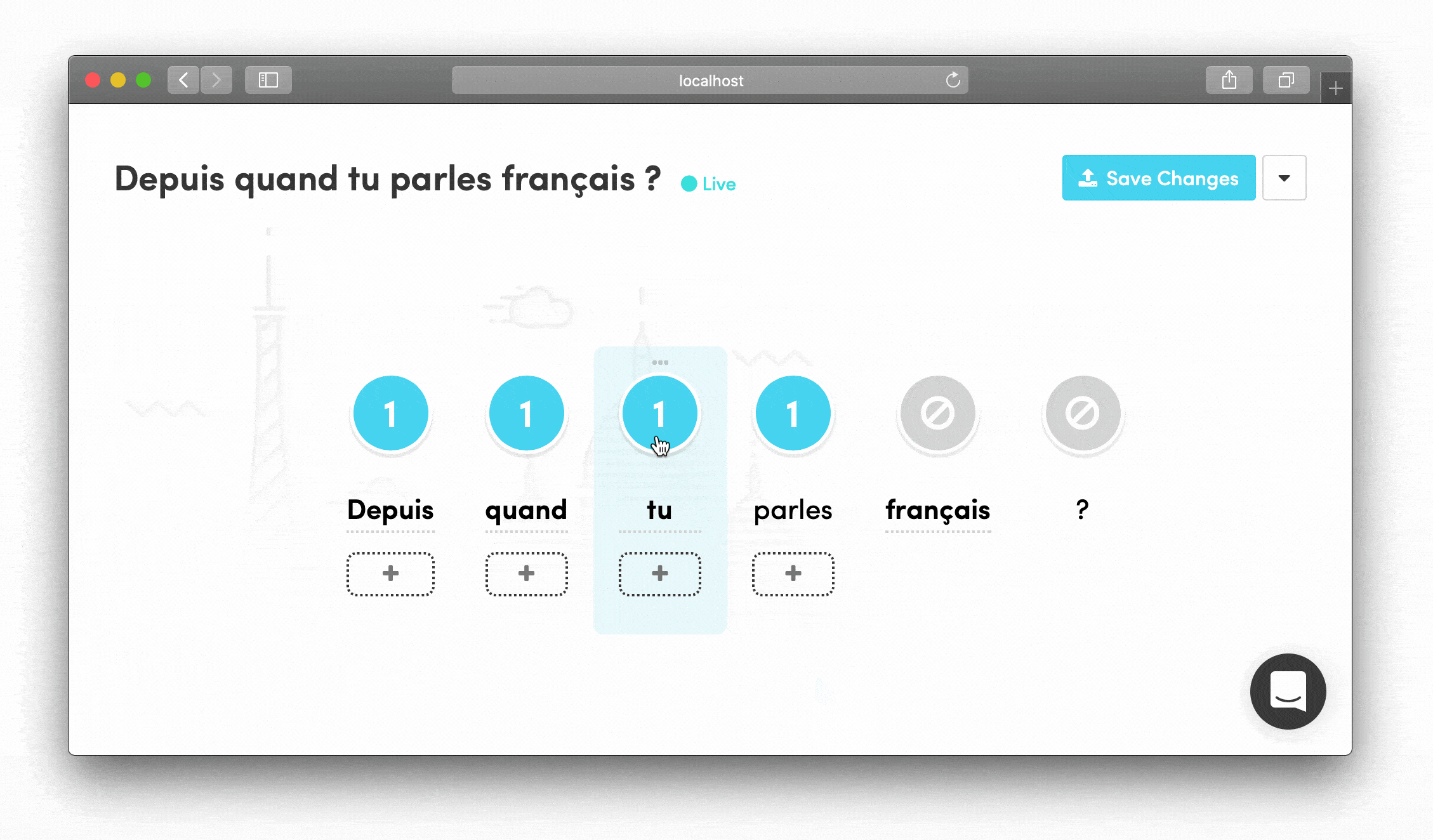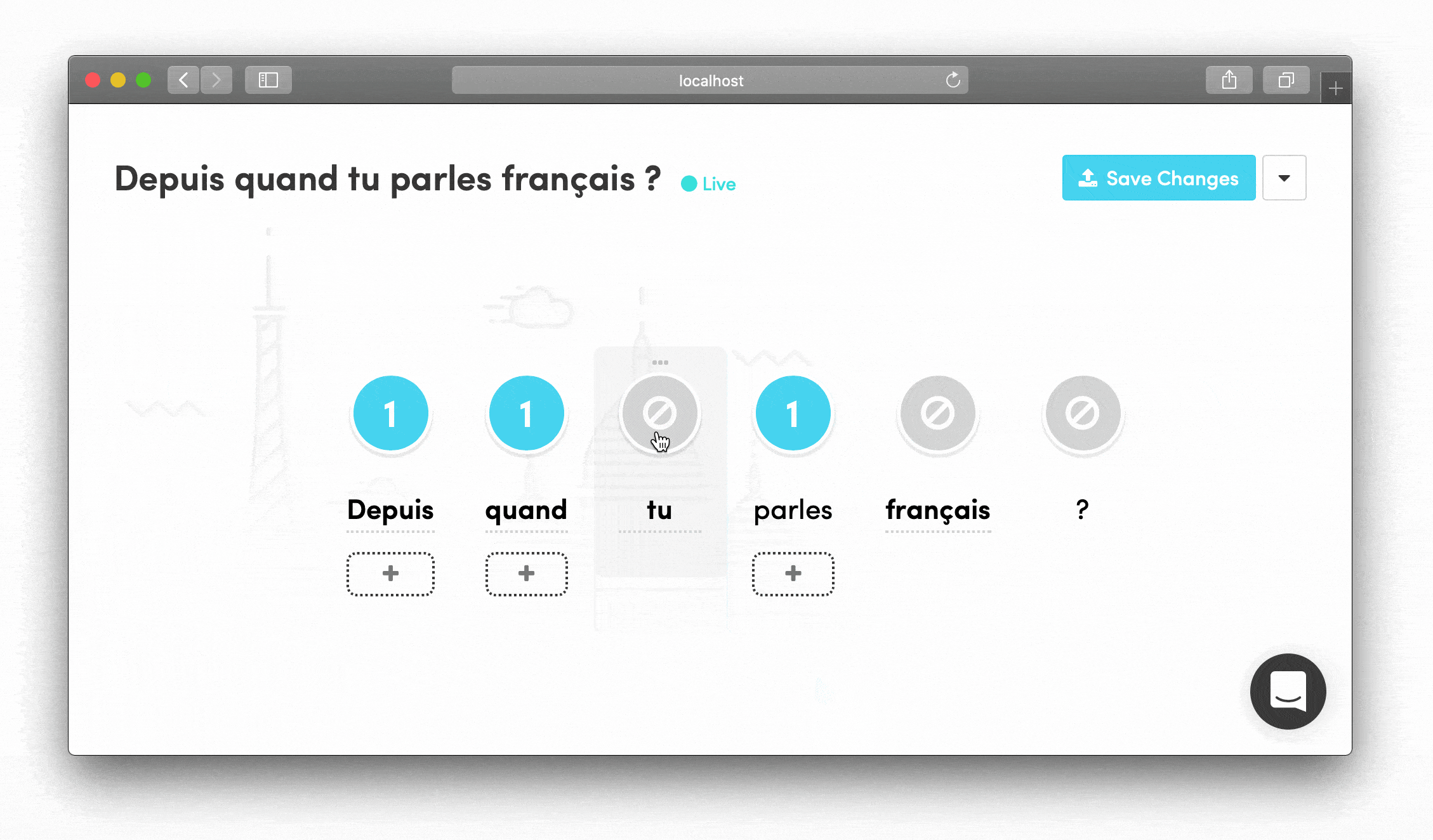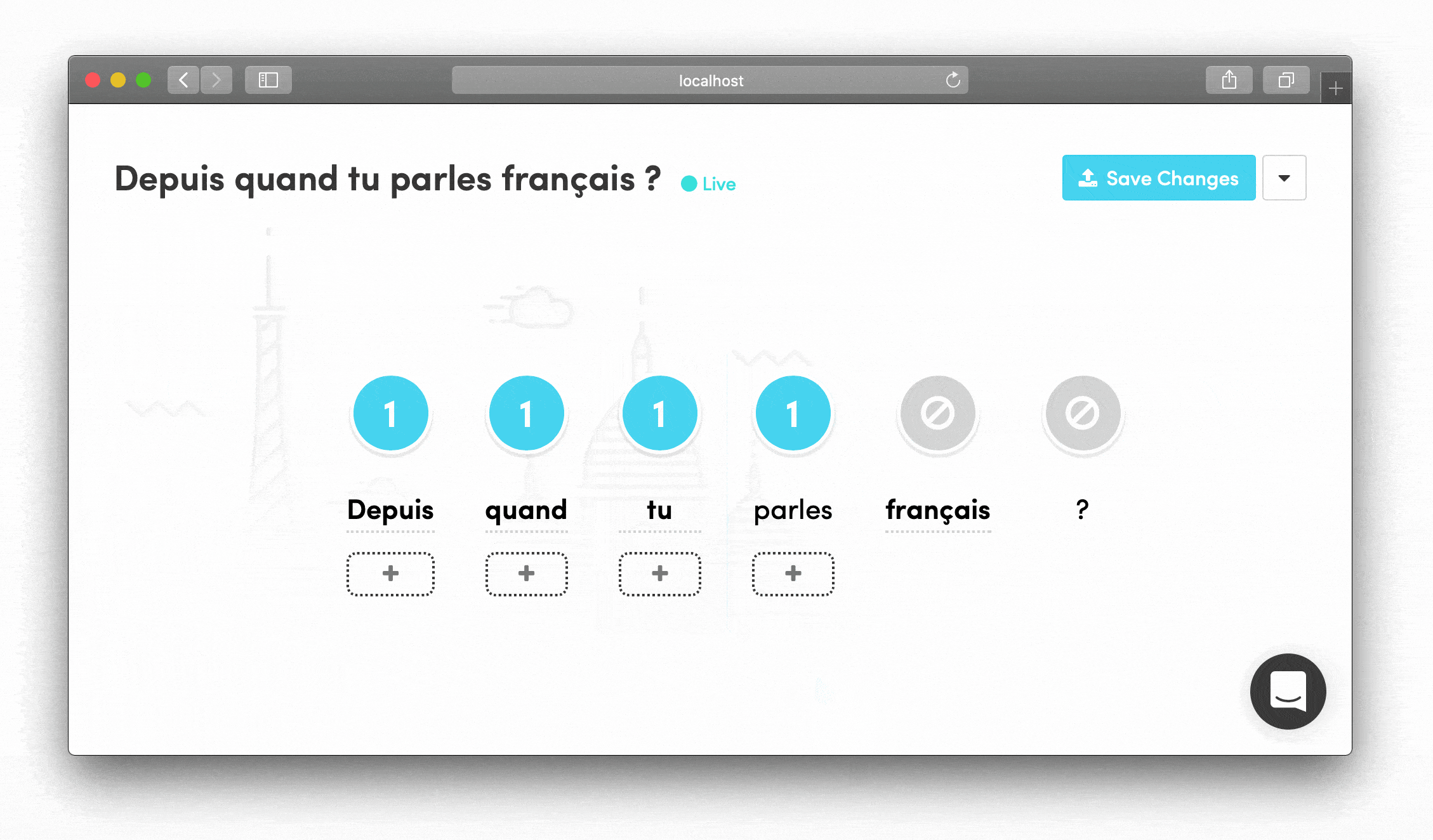
Drag-and-Drop Phrase Building Words could be rearranged by dragging, letting linguists see how phrases would flow and quickly experiment with different structures.
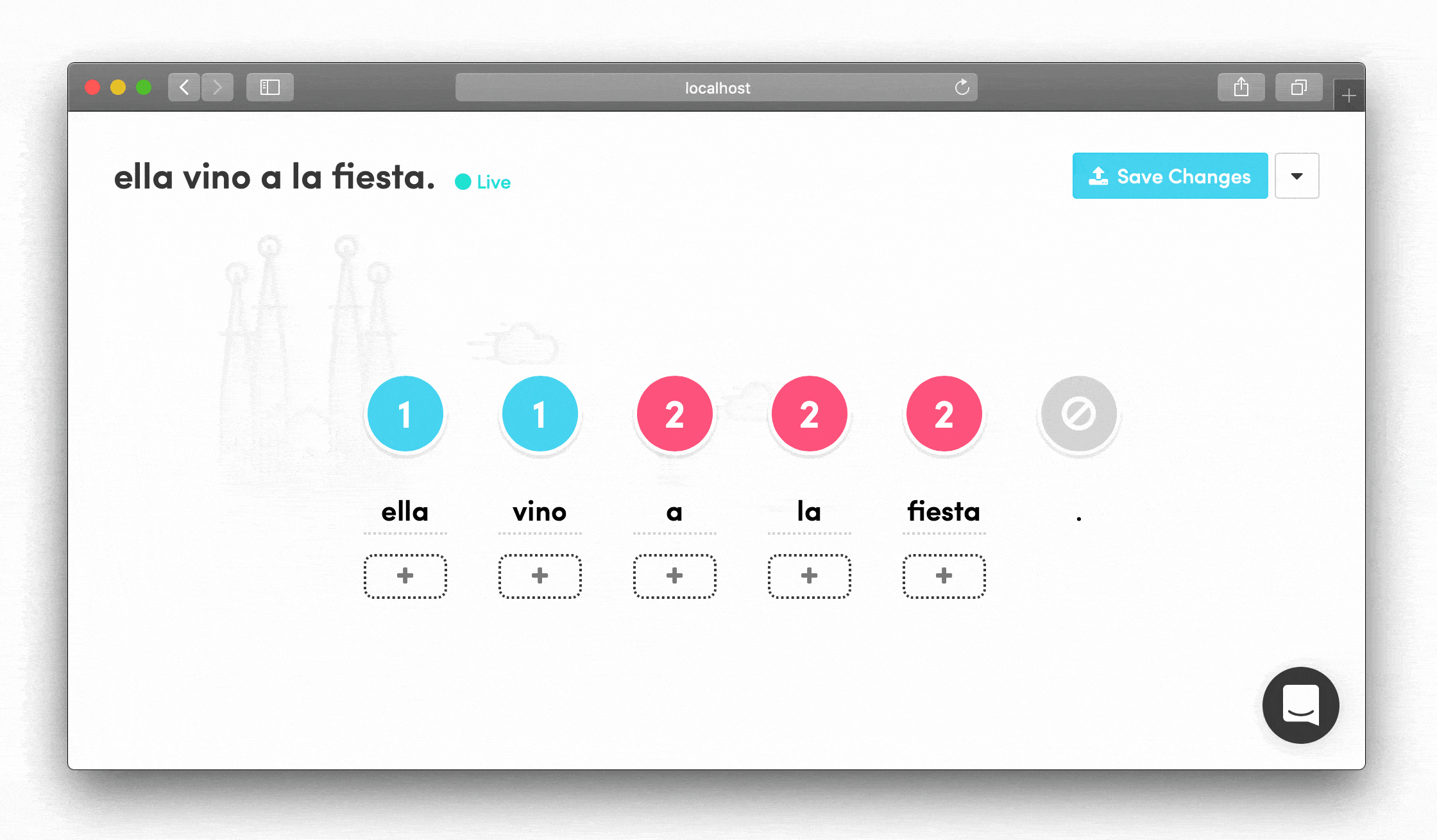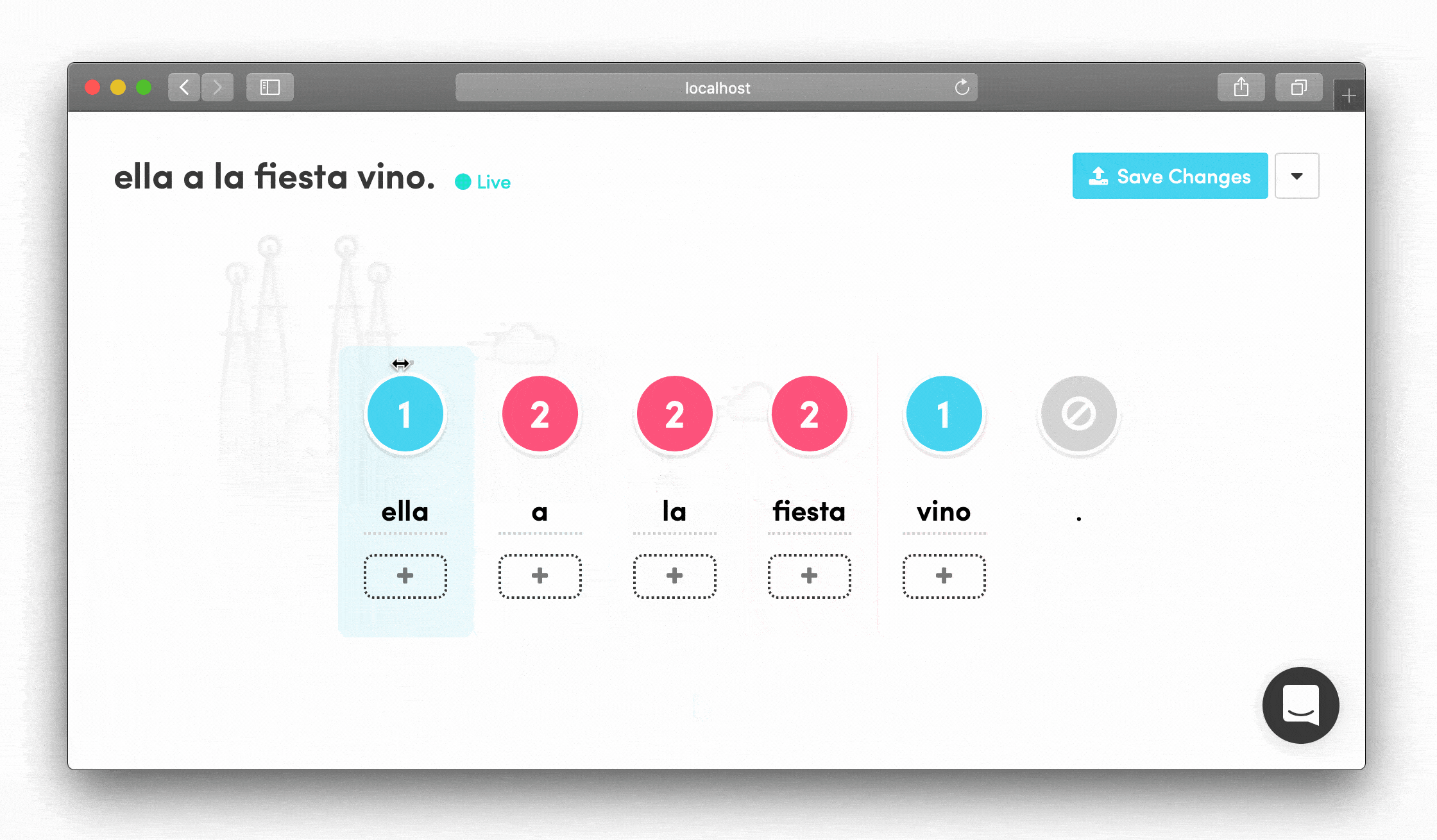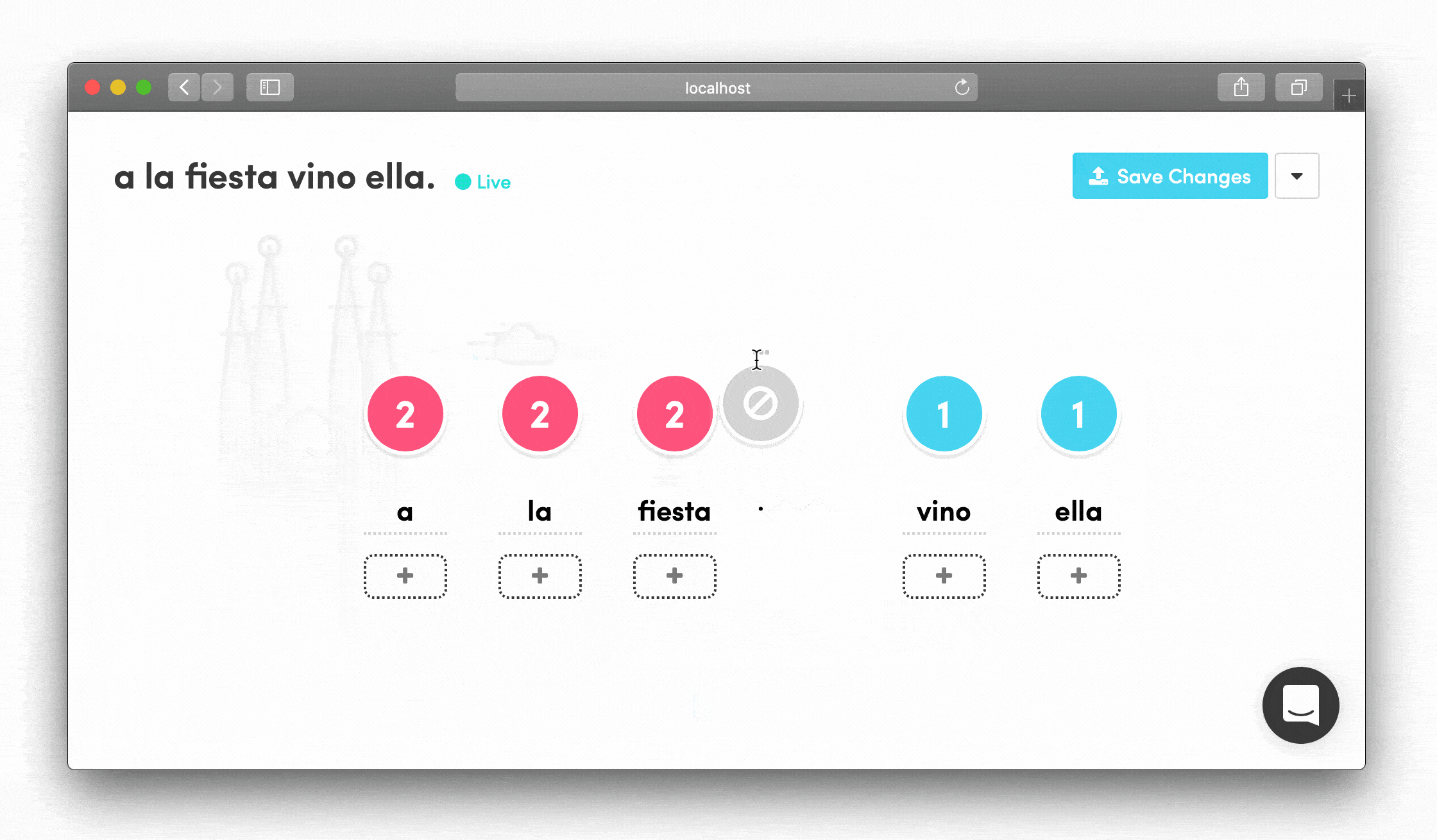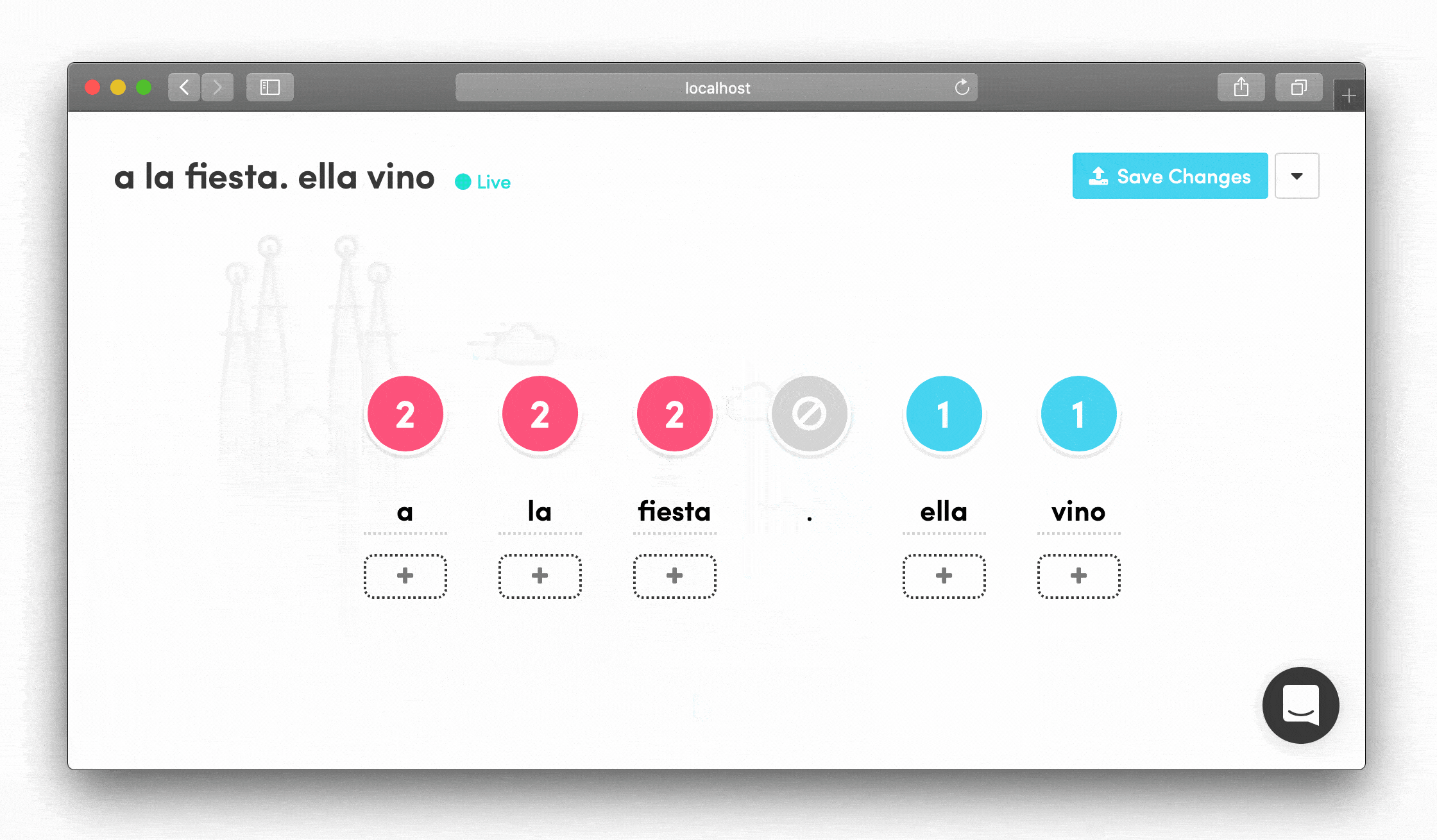
Forgiving, Self-Explanatory Interface The UI prioritized clarity over complexity. Everything had a clear purpose and immediate visual feedback.
The Deeper Challenge: Tokenization
Under the hood, tokenization turned out to be a surprisingly tricky problem: how do you properly break text into meaningful pieces across different languages?
French uses spaces before colons. German capitalizes more than just proper nouns. Spanish has inverted question marks. These aren't edge cases, they're fundamental to how these languages work.
If you're using Python, there's the powerful spaCy or NLTK packages to handle all this linguistic complexity.
In Ruby, however, there are exactly zero well-maintained, multilingual tokenisation gems at the time of writing this. So, I devised a lengthy but well-tested Regex to scan and tokenize the string, with additional rules based on the features of the language in question:
# Break the input into actual words (excluding spaces) tokens = initial_string.scan(/[^\s]+/).reject { |token| token == " " } # Handle punctuation as separate tokens based on language rules tokens = tokens.map { |token| token.scan(/[\]\[¡!"&()*+,.\/:;<=>¿?@\^_`{|}~-]+|[^\]\[¡!"&()*+,.\/:;<=>¿?@\^_`{|}~-]+/) }.flatten
As such, we don't need to store the phrase as a full string. Instead, its form is stitched back together according to the order of the words, which allows you to manipulate it.
Footnote on deciding to use React and GraphQL
Although internal tooling is often a domain where you can comfortably rely on Rails views (with a sprinkle of JS), Sequences was an exception. As you see from the interactions above, there is a non-trivial amount of editable and dynamic state going on, with implications for both function and form. Moreover, in any word within the sequence, there are subcomponents (the word, the coloured stepper and the list of responses) which are themselves interactive and conditionally rendered. It didn't take long after choosing React for it to be a net saving in cognitive overhead.
GraphQL (using Robert Mosolgo's graphql-ruby gem) was a complementary choice, for similar reasons. Sequences have lots of nested collections, from which we pluck specific fields, and this is handled cleanly and intuitively in GraphQL. Adding new features (like groups) becomes little more than adding a new field to the query string, and ensuring the flow of data is managed. By batching with Shopify's graphql-batch gem, we were also able to minimize the N+1 queries.