
Letterhead
Scaling a PDF API from 20 to 3,000+ RPM
During Y Combinator S24, I built Letterhead, a PDF generation API that handles 3,000+ requests per minute. This started from a frustrating personal experience while working with Weldmet: I couldn't find a PDF tool that worked the way I needed it to.
What began as scratching my own itch became a bigger challenge: building something simple on the surface, while handling all the complexity behind the scenes. This post explores both the technical journey of scaling across AWS, Azure, and GCP, and the design decisions focused on making the developer experience seamless.
The Problem
You're a developer about to build a PDF invoice feature—it seems straightforward enough. You've picked up the task of writing a feature that will create a PDF invoice/quote/receipt/ticket from your database and send it to the customer by email. You know that the most common way to generate PDFs is to load an HTML webpage into a headless Chromium instance, and then render an approximation of the content to PDF, using a library like Puppeteer to control your Chromium instance. So, you cook up a simple self-hosted Puppeteer worker (or use a managed solution like Browserless) that visits the template on your Ruby on Rails app, and creates your PDF. Your template has a few bits of conditional logic to check if fields are present or not, an iteration for line items and a blocking request for a custom QR code image, but nothing too complicated. Since your webpage loads fine, and it looks fine in a handful of actual PDF renders on development and staging, you ship the whole thing to production and a few days pass…
Uh oh! You've just been pinged by a team member that some customers are confused because they've received completely blank invoices. Some invoices show blocks of ☐☐☐☐ instead of text. Some are missing their QR codes. Some invoices got all scrambled because you tried to create a footer and its position has wildly offset the rest of the document because someone's address took 4 lines not the 3 you tested on. Other invoices have had their page break inserted in the middle of your boss' signature. The list of issues goes on.
What went wrong?
The real issue wasn't technical, it was about the developer experience. Building PDFs felt like it should be simple, but the existing tools forced you into a world of workarounds and uncertainty.
PDF template development requires testing how multiple input data variations and network conditions affect the final PDF output, not just the webpage preview. The webpage serves as a debugging artifact, but relying solely on browser appearance creates false confidence because:
- CSS properties (shadows, filters, backgrounds) and layout systems (flexboxes, sticky elements, absolute positioning) often render completely differently in PDF context.
- Page break behavior is fundamentally different from browser scrolling and cannot be reliably tested in the browser viewport.
- Font availability varies significantly between development machines and production rendering environments.
The workflow itself was broken. Each template change required a painful 4-step dance:
- Setting up ngrok tunneling to expose your local application
- Modifying template parameters and restarting services
- Manually invoking the PDF service endpoint
- Downloading and inspecting the generated PDF output
There was also no way to anticipate some conditions that only strike when you test at volume, or on your production server (like sporadically hanging third-party API requests or slow DB queries). Lastly, your attempt to get headers and footers to play nicely in Puppeteer forced you into a hack that broke your layout.
After wrestling with these problems myself, I realized the tools were optimized for the wrong thing. They prioritized features over the fundamental experience of building PDFs. I wanted to create something that felt right from the developer's first interaction, something that made sense the first time you tried it, without reading docs or fiddling with setups.
The Solution
For this solution to achieve meaningful adoption, it needed to satisfy two critical requirements:
- Make the simple things simple. PDF generation should feel as natural as writing HTML. No tunneling, no complex setup, no waiting around to see if your changes worked.
- Handle complexity invisibly. Scale, reliability, and edge cases should be solved behind the scenes. Developers shouldn't have to think about infrastructure or worry about production breaking.
Solving for Developer Productivity
Firstly, I needed a faster way to see the results of my changes to the template code. At the most basic level, I wanted an HTML editor on one side, and a preview of the generated PDF from the API on the other side. In that way, I could tweak code, hit ⌘ Enter and see the result with the only delay being the time to render. The first iteration of the tool did only that, but immediately felt like a step in the right direction:
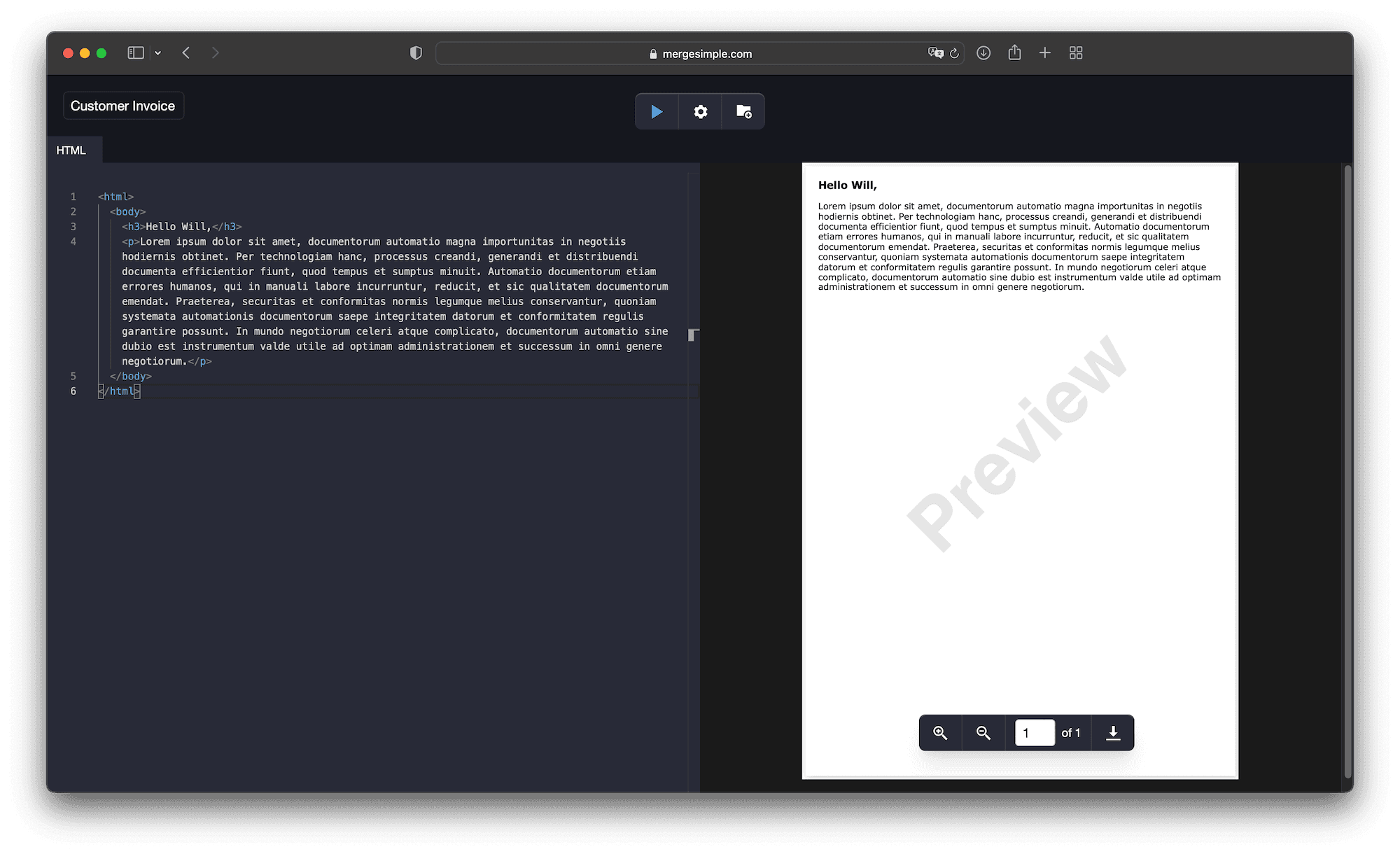
But I noticed another friction point: copying HTML back and forth between my local server and the editor. Still too much context switching. Good developer experience means working in one place.
So I built template rendering directly into the tool. I chose Liquid as the templating language—simple, familiar, and powerful enough for most use cases. Added a JSON editor for variables so you could test different data scenarios instantly.
The result was a mini-IDE where you could iterate on both code and data with the same immediate feedback loop:
I can then simply ping a request to api.letterhead.dev/v1/pdf. The request body is just the JSON I've been testing in the editor all along:
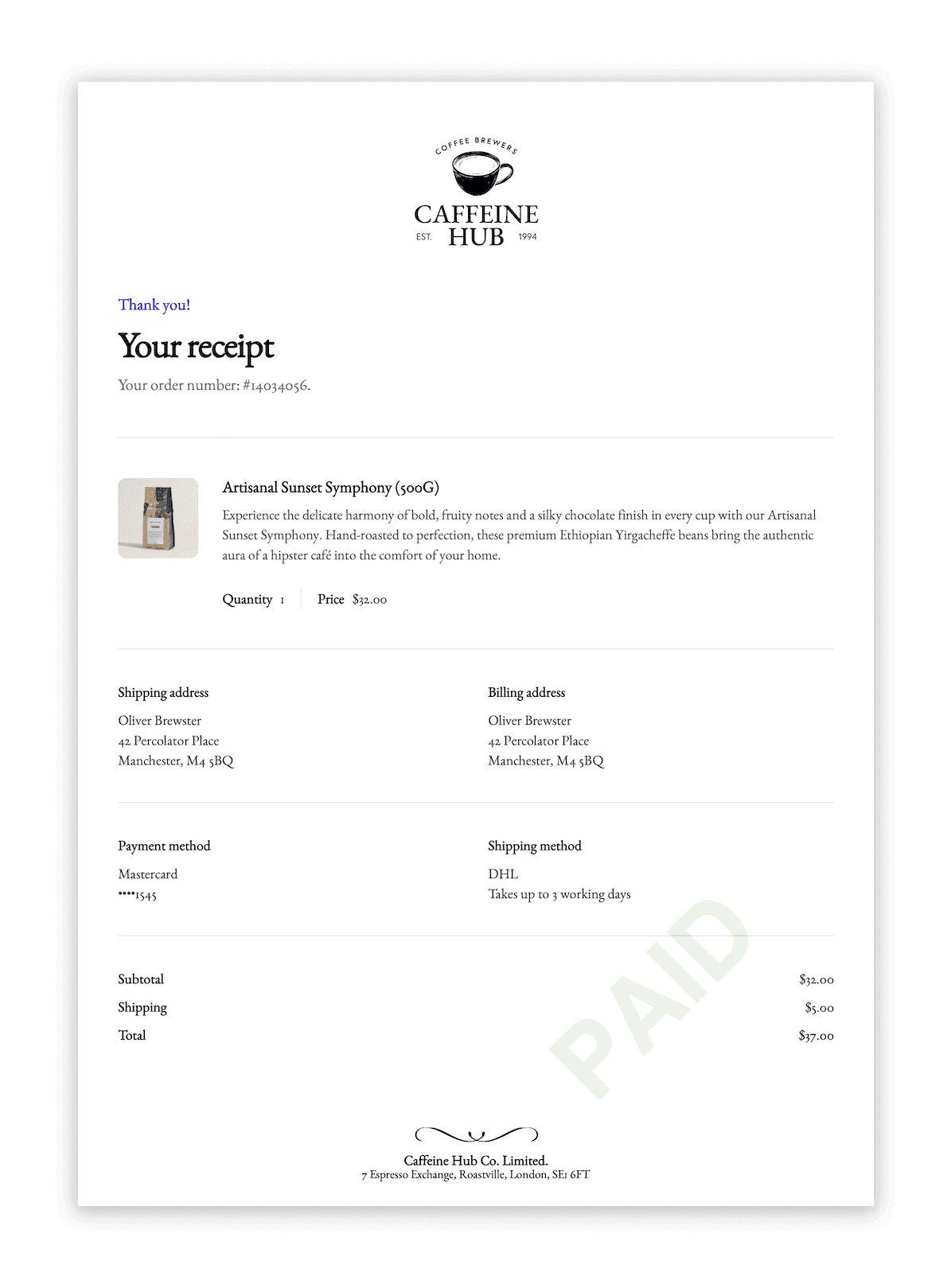
{ // Specify your template ID and version "template": "customer-receipt@latest", // Supply the variables for use in the template "variables": { "name": "Oliver Brewster", "orderNumber": "14034056", "lineItems": [ ... ], "shippingAddress": [ ... ], "billingAddress": [ ... ], "itemsSubtotal": "$32.00", "shippingSubtotal": "$5.00", "total": "$37.00" } }
Resulting in production-quality output:
Solving for Simplicity: Headers and Footers
TLDR; Headers and footers in Puppeteer are very limited.
Puppeteer provides functionality to create three separate viewport contexts: header, content, and footer. These viewports render completely isolated HTML snippets that get composited into the final PDF. However, since all headers (and footers) across pages must share identical HTML, there's no mechanism for conditional page-specific content. You can either apply the same headers/footers to all pages or no pages, there's no middle ground. To work around this limitation, developers typically embed headers and footers directly in the document content and manually calculate vertical spacing, which is both technically challenging and error-prone at scale.
The Letterhead approach implements a fundamentally different architecture. Instead of relying on Puppeteer's native functionality, I developed three parallel Puppeteer worker processes that handle header, content, and footer rendering independently. Before PDF capture, two additional workers manipulate the DOM to generate documents with identical page counts to the primary content document, but containing only the selected header/footer elements for each page.
The API enables sophisticated header/footer configuration through a declarative interface:
{ "headers": [ // Show the primary header on pages 1, 2 and 3 only { "selector": "#primaryHeader", "pages": [1, 2, 3] }, // Show the secondary header on page 4 onwards { "selector": "#secondaryHeader", "pages": "4..." }, ] "footers": [ // Show the footer on all even-numbered pages, except the last { "selector": "#footer", "pages": "even", "excludePages": [-1] }, ] }
The system then merges the three document layers, automatically calculating appropriate content padding to accommodate the header and footer layers:
In this way, you can use headers and footers to do exactly what you need to do. The good news, too, is that by running these two extra workers in parallel with the original 'content' worker, the additional work doesn't create noticeable latency.
Solving for Scale
The tool was working beautifully for my own needs, but quality means thinking beyond just your own use case. Other developers would have different patterns: bursts of thousands of documents, edge cases I'd never considered, expectations for reliability that go beyond "works on my machine."
That's when scaling became the real test. I had to ensure the API could handle serious production workloads while maintaining the same simple experience. No one should have to think about infrastructure when they just want to generate a PDF.
AWS
Until this point, I had been using Serverless Framework (on AWS Lambda) to run Puppeteer and Chromium, but I hadn't tested how my deployment would scale beyond the small number of requests I was firing at it. Using a simple Locust script (on LoadForge), I ran tests to incrementally spawn more requests with complex payloads. I quickly found the first limit of the API. After every burst of ~20 requests, Linux would throw the exception EMFILE: too many files open which would timeout the current request, and trigger a cold start for the following request. To dig deeper into why this was happening, I switched on Enhanced Monitoring for the Lambda function and traced the maximum of fd_use (namespace: /aws/lambda-insights) through CloudWatch Metrics:
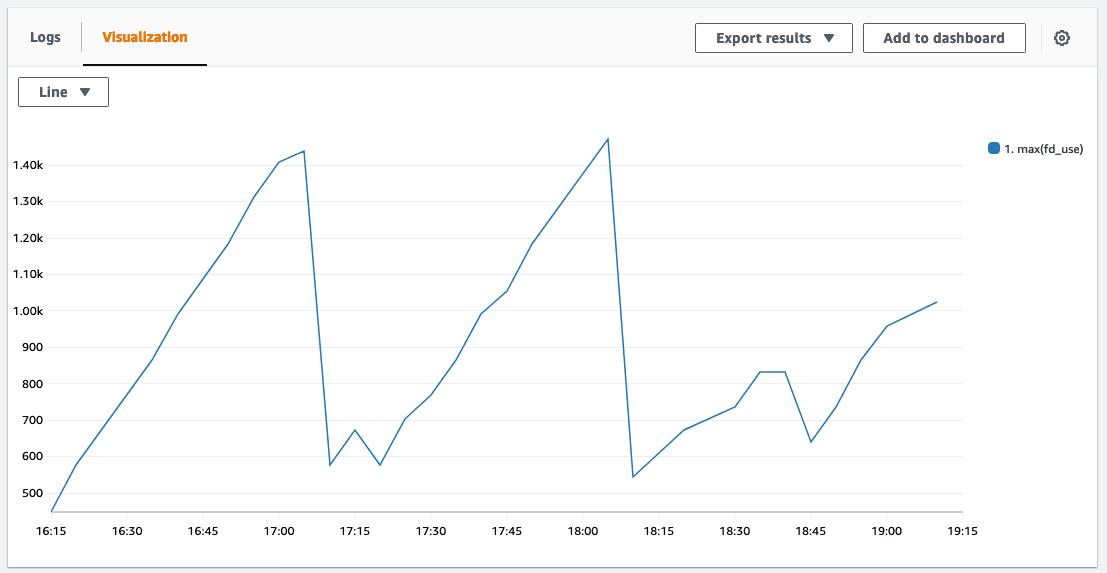
The data revealed file descriptor accumulation due to Lambda's container reuse strategy across request bursts within the same region. When the spike reached Lambda's 1024 file descriptor limit, requests failed and containers were destroyed. I identified and resolved connection disposal issues in the application code, reducing the leak rate per request. However, file descriptors continued leaking despite these fixes. Further investigation revealed that the leaks occurred even during minimal Puppeteer initialization without any network operations, indicating a platform-level issue rather than application-level bugs. As an interim solution, I implemented a health monitoring system (based on samswen's fix) that tracked file descriptor usage and preemptively triggered container resets with process.exit(1) before reaching critical limits. While this prevented exceptions, it was fundamentally a hack that relied on container destruction and cold restarts after every 15-request burst. Given this apparent platform quirk, I decided to evaluate alternative deployment targets to determine if the issue was AWS-specific.
Azure
I ported the API over to Azure's serverless platform, Azure Functions, to find that the file descriptor leak was gone. The same codebase could now handle nearly 60 requests per minute (RPM) in the load tests. The issue with Azure was velocity of autoscaling.
Like other serverless platforms, Azure Functions allows configuring maximum concurrent requests per instance. This is controlled through the host.json configuration:
"extensions": { "http": { "maxConcurrentRequests": 1, } }
Having a maximum concurrency value of 1 means that for every inbound request, Azure will provision one dedicated compute instance (or 'host' in Azure-speak). This caters safely for the memory-hungriness of Chromium.
However, the Consumption Plan in Azure sets a hard limit on the rate at which new instances can be provisioned: 1 new instance per second. This is OK if you have high concurrency (100+), as many web APIs do, because it's a safer bet that enough time will elapse before you need that next instance. But with my ultra-low concurrency of 1, Azure needed to be constantly spinning up new instances to handle every uptick in traffic. Although instances are kept around for possible reuse in a 10-minute window after each invocation, during spikes of traffic the rate of new instances would easily exceed 1 per second and Azure would start returning 429: Too many requests.
To get Azure to increase this provisioning limit to 2 new instances per second, you must upgrade to the Premium Plan which introduces a minimum fixed cost of ~£200 per month. In fact, to build any production-ready API on Azure Functions, there seems to be no escaping the Premium Plan. For example, it's also a prerequisite to reserve any warm instances (to prevent cold starts) for your functions. I expected some costs for maintaining warm instances, but I couldn't justify a high monthly subscription for a hobby project without users at that point. I decided to continue shopping around, and see how far I could go with GCP.
GCP
Moving onto the third and last serverless offering, I began experimenting with Google Cloud Platform (GCP). Like AWS and Azure, GCP offers two primary ways of doing serverless:
- Application Code Only. You don't have to worry about the underlying runtime or the environment, as the cloud provider manages these aspects. But you trade convenience for control.
- Docker Container. You provide a Docker image which contains your application code along with the necessary runtime and dependencies. The cloud provider runs your function inside this container, which lets you control your exact setup.
Having used the 'application code only' approaches before in AWS and Azure, this time around I decided to create a custom Docker image for the API and deploy it through Google CloudRun. On reflection, Docker made much more sense for my use case and I should have been using it earlier. With a Docker container, I could now control the discrepancies between the development and production environments, and version control changes to the environment (there are dozens of Chromium dependencies) along with my application code. To fill the gap left by the runtime environment, I chose Express for its simplicity, speed, composable middleware, and as an opportunity to learn something new.
Free from the autoscaling rate limit imposed by Azure, the first round of load tests on CloudRun were able to hit ~200 RPM before a bottleneck of a different kind emerged.
Concurrency
The first bottleneck that emerged on the GCP deployment was related to concurrency.
To explain this, it helps to have a mental model of the architecture of the API. At this point, it's a single Express API that exposes two routes, which correspond to the controller and worker functions in the diagram below.
The controller here is responsible for routing the initial inbound request from the client, and processing the payload. The controller then invokes up to three workers to render the actual PDFs, which the controller finally stitches together and returns to the client as a single document.
Ok, now back to the concurrency problem. Because the API was deployed in a single container image (and a single CloudRun service) I could only set a single concurrency value for the whole API (containing both controllers and workers). That meant that even requests to the controller, which doesn't use Chromium at all, are given one dedicated instance each. This is a massive overallocation of available compute, and so bursts of requests would quickly eat the GCP regional quota of 30 instances per region. I solved this first bottleneck by splitting out the controller from the workers, as separate Docker images and deployments. Controllers are then assigned a far higher concurrency, and a slimmed down image, so they can scale far more conservatively than the worker pool. This change allowed the API to reach 500 RPM.
Load Balancing: Unlocking 1,000 RPM and beyond
Rerunning the load tests, the API hit another spate of error codes at ~1,000 RPM. Similar to the autoscaling issue with Azure Functions, the acceleration of requests was outpacing the ability of CloudRun to provision new instances in the same region, and the familiar 429 error code was back. To unblock this issue, I deployed the same CloudRun image to several different GCP regions in Europe, and set up a global external load balancer to allocate the requests with the round robin policy, allowing each region to scale up more gracefully. The Load Balancer helped the API reach 1,300 RPM before the 429 error crept back in again.
These new failures were arising in edge cases where the load balancer picked a region to route to which was already overwhelmed. I wanted to implement some retry logic in front of the load balancer, for this I turned to Cloudflare Workers. Cloudflare Workers are lightweight functions that run on the V8 engine and are deployed at the edge of Cloudflare's network, providing low latency access. They are cheap and fast, making them ideal for high-volume API traffic. I wrote a simple retry handler to run in the worker, which sits in front of the load balancer:
export async function handleRequest(request: Request): Promise<Response> { const originalResponse = await fetch(request); if (originalResponse.status === 429) { // Uh oh! We're scaling too fast, let's try again in 3 seconds. await new Promise((resolve) => setTimeout(resolve, 3000)); // Retry the request return await fetch(request); } else { return originalResponse; } }
And deployed it with Wrangler CLI as part of the same CI/CD workflow as the API itself.
The last handful of test failures cropped up at 1,500 RPM when the load balancer would naively retry the same region again, even after the previous request had been to that region and failed due to being overloaded. To handle this rare edge case, and to gain more nuanced control over the availability of individual regions, I decided to write a primitive load balancer to run in the Cloudflare Worker itself (using KV storage for persisting node availability data) and then shelved GCP Load Balancer:
This dealt with the issue by not re-attempting already overwhelmed regions. I was able to let the load tests scale error-free to 3,000 RPM for 10 minutes. Conceivably, it could have been pushed further but the costs of such load tests were becoming non-trivial! For my initial prototype, this felt like a good place to stop my quest for scale for now.
This whole scaling journey reinforced something important: good design engineering isn't just about the interface you see. It's about making sure every part of the system, even the invisible ones, worked in service of the developer using it.